Qu’est ce que GIT ?
Git ? Garage des Iguanes et des Tortues ? Grande Italienne Triste ? Gilles Intègre Tout ?
Non en fait, c’est un logiciel de gestions de versions décentralisé développé par Software Freedom Conservancy. Il s’agit du logiciel de gestion de versions le plus populaire.
C’est vraiment utile d’apprendre et d’utiliser ça quand on commence en développement ? Quand on est junior ?
Et bien… oui !! Parce qu’on l’utilise tout le temps ! Que ce soit pour un projet perso, un projet pro, le projet de Michel, ton pote qui a un bug sur son appli et qui t’appelle à l’aide, ou bien le projet de ta vie que tu montes en équipe avec Raph et Cédric, tes potes devs.
Tu vas même l’utiliser pour régler le bug d’un énorme projet open-source ! Parce que oui, c’est super simple en fait ! (pas le débuguage du projet hein 😉) mais de récupérer, de travailler et de renvoyer le code.
Un logiciel de gestion de versions ?
En fait on appelle ça du versionnage de code. Ça consiste à gérer l’ensemble des versions d’un ou plusieurs fichiers.
C’est un outil qui se veut simple et performant, dont la principale tâche est de gérer l’évolution du contenu d’une arborescence.
En gros, il va gérer (pas tout tout seul mais presque 😉) toutes les modifications qui auront lieu sur tes fichiers, et surtout, stocker toutes les versions de tes fichiers !
Par exemple, tu développes un site pour Jean, Jean veut un formulaire de contact (nom, prénom, mail) que tu codes. Simple. Sauf qu’un mois après, Jean veut ajouter un champs pour le numéro de téléphone à son formulaire. Tu l’ajoutes et tu “commit” (on le verra plus tard mais entends “sauvegarde”) et hop ! c’est en ligne.
Et bien Git va sauvegarder les deux versions du code, celle sans et celle avec le champs “téléphone”. Et, puisque c’est sauvegardé, tu pourra voir les modifications et revenir dessus au besoin.
Tout est sauvegardé sur mon ordinateur ?
Oui ! sous forme de petit dossier cachés .git .
Mais on utilise aussi des services d’hébergement comme GitHub ou GitLab (pour ne citer qu’eux pour l’instant) où l’on va stocker notre code ainsi que les différentes versions. C’est aussi grâce à cela que tu vas pouvoir bosser sur le projet de Michel, avec Raph et Cédric ou bien le projet open-source (il faut bien que tout le monde puisse y accéder non ?).
Il faut savoir que quand un fichier n’est pas modifié, le fichier n’est stocké qu’une seule fois. En revanche, comme je l’ai dis, si le fichier est modifié, les deux versions sont stockées.
Et… ?
Attends, tu as compris ? Si tu as pas tout compris je t’invites à relire tout ça, parce que sinon,… courage 😓😂.
C’est tout bon ?
Bon maintenant je vais te montrer comment installer Git sur ta machine (PC, Mac, Linux, comme tu veux 😉)
Installons Git
Git c’est un logiciel qu’il va falloir installer et que tu vas utiliser en grande partie dans ton terminal.
Pour le télécharger et l’installer, c’est ici ! (https://git-scm.com/downloads)
Choisis ton système d’exploitation et suis les indications.
Si tu as besoin d’aide, je te renvois sur les installations de Grafikart qui l’explique très bien :
Une fois fait, eh bien je te propose de regarder si Git a été correctement installé en ouvrant un terminal et en tappant :
git --version
Si tu as effectivement un numéro de version qui apparaît, alors c’est tout bon !!
On aura accès à la documentation de Git avec la commande :
git helpOn commence ?
La configuration
Dans un premier temps, on va configurer rapidement Git.
Dans ton terminal tu vas pouvoir “parler” à Git et interagir avec lui.
On va donc configurer Git avec la commande (attends avant de faire 😉):
git configà laquelle on va donner des options. On va configurer le nom d’utilisateur et ton adresse email (tu peux faire 😉):
git config --global user.name "Nom Prénom"
git config --global user.email "nom@exemple.com"Le drapeau —global permet d’indiquer à Git que cette configuration est globale et affectera ainsi tous nos futurs projets.
Premier commit
On va commencer par créer un dossier là où tu veux créer ton projet.
Pourquoi ne pas le faire en ligne de commande ?
Pour commencer on lui donne un chemin (celui que tu veux) :
cd ton/cheminEnsuite on va créer un nouveau dossier :
mkdir premier-projet-gitPuis on va rentrer dans ce dossier :
cd ./premier-projet-gitet on va initialiser le projet git dans ce dossier :
git initET VOILÀ !! Git est initialisé dans le dossier !
On va pouvoir créer un fichier ‘Readme.md’ dans le dossier dans lequel on va donner les informations importantes du projet (Pour l’instant on va s’en tenir au nom):
touch Readme.md(Si jamais la commande ‘touch’ ne fonctionne pas, pas de panique, il suffit de créer un fichier texte en faisant un clic droit et de changer le .txt en .md 😉)
Et dans ce fichier on va écrire le nom de notre projet :
"# Premier-projet-git"Mais… du coup, on vient de faire une première étape dans notre projet ! On devrait en garder une trace !
On va regarder l’état de notre projet avec la commande :
git status
Ça, ça veut dire qu’on a un fichier qui n’a pas été traqué, pas été ‘stage’. En gros il faut lui dire que le fichier ‘Readme.md’ a été modifié et sera pris en compte pour le prochain commit (la prochaine ‘sauvegarde’).
On va donc l’ajouter comme ceci :
git add Readme.mdEt pour vérifier on refait un :
git status
C’est plus joli en vert non ? 😉
On vient d’ajouter notre fichier à la file d’attente prête à être ‘commit’. Et pourquoi attendre plus longtemps avant de le faire ?
git commit -m "Mon premier commit"
Bravo !!
Tu viens de faire ton premier commit !
Pour t’expliquer la commande git commit permet de faire ton commit, et l’argument -m permet de noter un message expliquant les modifications des fichiers de ton commit (ça c’est obligatoire si tu ne veux pas te perdre).
Fichier .gitignore
Le fichier .gitignore, même si son nom fait un peu peur, c’est un simple fichier texte dans lequel on va mettre tous les fichiers que l’on veut ignorer. Par exemple, ça va être des fichiers de configuration, des fichiers thèmes, etc.
Pour le créer on va faire comme notre fichier Readme.md de tout à l’heure :
touch .gitignoreEt dedans on met par exemple tous les fichiers .tmp :

En faisant cela, tous les fichiers finissant par .tmp (les fichiers temporaires) seront ignorés par Git.
Pour être plus efficace il existe le site gitignore.io dans lequel on va pouvoir mettre toutes les technologies que l’on utilise pour que notre gitignore soit le plus complet possible suivant notre projet.
On va donc commit notre fichier .gitignore :
git status
git add --all
git commit -m "add .gitignore"Mais, comment je peux voir mes commit du coup ?
Parce que oui, c’est ça qui est intéressant 🤷♂️
Et bien avec cette ligne :
git logOn obtient ça :

On a alors plein d’infos ! Ligne par ligne ça donne :
‘commit’ ➡ l’identifiant du commit
‘Author’ ➡ L’auteur du commit
‘Date’ ➡ La date du commit
et le nom qu’on a donné à notre commit.
Lorsqu’on va avoir besoin d’identifier un commit et de l’utiliser on prendra l’identifiant du commit en question.
Pour avoir quelque chose de plus lisible on peut faire :
git log --onelineCe qui donne :

Avec seulement l’identifiant et le nom du commit.
Une dernière chose là dessus, si je viens à faire une modification sur mon fichier .gitignore par exemple, en modifiant “*.tmp” en “*.tmpgit” et je le commit, si je veux voir les modifications par rapport à mon dernier commit, je fais :
git diff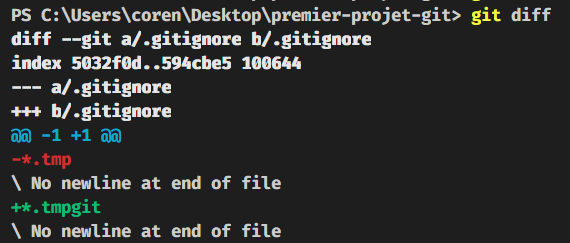
On voit alors que depuis le dernier commit, sur le fichier .gitignore, une ligne a été modifiée. “*.tmp” est devenu “*.tmpgit”.
Je peux revenir en arrière ?
C’est le gros intérêt du versionning !
Il y a plusieurs façon de le faire :
Avec la commande CHECKOUT,
on peut passer de branche en branche (on en parlera juste après), revenir sur un commit et revenir sur un fichier par rapport à un commit.
Suite à notre dernière intervention sur le .gitignore, le “*.tmp” est devenu “*.tmpgit”.
Pour nettoyer cela et revenir à “*tmp” on commence par le modifier dans notre fichier :
et on le commit :
git add --all
git commit -m "clean gitignore"puis on va regarder quelles ont été les modifications sur .gitignore :
git log --oneline -p .gitignore
On veux aller voir au commit initial du gitignore, soit le commit “8bc2bdf”.
Pour voir l’état de ce commit on va faire :
git checkout 8bc2bdf
On est sur la “sauvegarde” 8bc2bdf (du nom “add gitignore”).
Nous sommes remonté dans le temps sur le commit “add gitignore” et avons donc toute la hiérarchie de fichier du moment précis où l’on a fait ce commit (“add gitignore”).
Il faut savoir que si tu veux changer quelque chose tu devra commit, mais si tu commit et que tu reviens au “présent” avec : git checkout master le commit ne sera pas pris en compte, il sera enregistré mais pas pris en compte.
Si l’on veut modifier le fichier gitignore pour revenir à celui du commit “add gitignore” (même si ici ça n’a pas d’utilité), on ferait :
git checkout 8bc2bdf .gitignorepuis on ferait un commit.
Ce qu’on a fait, c’est qu’on a recupéré le fichier .gitignore à l’état du commit “add gitignore” et on a dit à git que c’était cette version qu’on va garder. En gros on revient en arrière.
On récupère une ancienne version d’un fichier que l’on remet au goût du jour.
Pour revenir au présent on peut faire :
git checkout masterAvec la commande REVERT,
on peut défaire, inverser un commit.
C’est à dire qu’on va défaire ce qui a été fait au moment du commit en créant un nouveau commit. Ca n’altère donc pas l’historique mais ça ajoute un commit d’inversion.
Par exemple, ajoutons un fichier index.html :
touch index.htmlPuis “commitons”-le :
git add --all
git commit -m "add index.html"Pour défaire ce commit avec “reverse”, on va regarder le nom du commit :
git log --oneline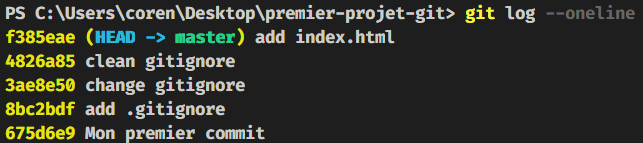
On voit qu’il a l’indentifiant f385eae.
Pour le défaire on va faire :
git revert f385eaece qui nous ouvre ça :

Il s’agit de Vim, c’est un éditeur de texte. On peut changer le nom du commit, ici “Revert “add index.html"", et pour terminer écrire :wq ou sauvegarder le fichier puis fermer le fichier de l’éditeur (Ctrl + w).
Avec un coup de git log on peut voir que notre revert a bien fonctionné :

Si on regarde dans l’arborescence, index.html n’est plus là :

Avec la commande RESET,
on peut également faire plusieurs choses.
Il faudra être prudent lors de son utilisation car, contrairement à revert elle altère l’historique = dangereux et si tu vois —hard = très dangereux !
Pour la démo on va créer un fichier indexDeux.html, contact.html, article.html :
touch indexDeux.html contact.html article.htmlDans “indexDeux.html” on va mettre :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Accueil</title>
</head>
<body>
<h1>PAGE ACCEUIL</h1>
<h2>Git workflow</h2>
</body>
</html>Ca sera notre page d’accueil.
Dans “contact.html” on va mettre :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>contact</title>
</head>
<body>
<h1>PAGE CONTACT</h1>
</body>
</html>Et dans “article.html” on va mettre :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>article</title>
</head>
<body>
<h1>PAGE ARTICLE</h1>
</body>
</html>Avec git status on voit que nos trois fichiers ne sont pas traqués, on fait donc un coup de git add --all puis un git commit -m "add indexDeux.html contact.html article.html".
Donc voici les cas d’utilisation de git reset avec une démonstration à (presque) chaque fois.
git resetSupprime un fichier de la zone de staging mais pas les modifications qui sont faites.
git reset id-commitExemple :
Sur “contact.html” on change le html en ajoutant :
<h2>Voici comment me contacter :</h2>en dessous du <h1> déjà présent et on stage. (On ne commit pas !)
git add --allPour supprimer ce fichier de la zone de staging (sans supprimer les modifications) on fait :
git reset contact.htmlSupprime tous les fichiers de la zone de staging mais pas les modifications qui sont faites.
Même fonctionnement que celle d’au dessus mais pour tous les fichiers :
git reset❗ A utiliser avec précaution ❗ elle renvoit le dossier de travail au niveau du dernier commit. Toutes les modifications non commit seront perdues.
git reset --hardExemple :
Dans le dernier exemple on a ajouté un “h2” à la page “contact.html”, on ne l’a pas commit (tu peux vérifier qu’il n’est pas stage avec git status).
Au niveau des commit nous sommes toujours à “add indexDeux.html contact.html article.html” (Tu peux vérifier avec git log --oneline).
On va donc revenir à l’état du commit “add indexDeux.html contact.html article.html” sans garder les modifications (notre h2) :
git reset --hardEt on peut voir que le “h2” a disparu, que notre zone de staging est propre et que notre dernier commit est toujours “add indexDeux.html contact.html article.html”.
Permet de revenir en arrière jusqu’au commit en question, réinitialise la zone de staging tout en laissant votre dossier de travail en l’état. L’historique sera perdu (les commits suivant le commit en question seront perdus, mais pas vos modifications). Cette commande permet surtout de nettoyer l’historique en resoumettant un commit unique à la place de plusieurs “petits” commit.
git reset id-commitExemple :
Si on ajoute la ligne :
<h2>Je suis un h2</h2>à indexDeux.html et qu’on commit :
git add --all
git commit -m "add h2 in indexDeux.html"à contact.html et qu’on commit :
git add --all
git commit -m "add h2 in contact.html"et à article.html et qu’on commit :
git add --all
git commit -m "add h2 in article.html"on a donc ça :

ce qui, on ne va pas se mentir, est loin d’être propre.
Alors pourquoi ne pas regrouper tous ces commits en un ?
C’est ce qu’on va faire avec :
git reset 293b535pour revenir au commit antécédent (“add indexDeux.html contact.html article.html”) sans perdre les modifications.
Maintenant, on va commit toutes nos modifications sous un seul commit :
git add --all
git commit -m "add h2 in indexDeux.html contact.html article.html"
C’est plus propre non ? 😉
❗ A utiliser avec beaucoup de précautions ❗ Permet de revenir au commit en question et réinitialise la zone de staging et le dossier de travail pour correspondre. Toutes les modifications, ainsi que tous les commits fait après le commit en question seront supprimés.
git reset id-commit --hardLes branches
Imagines que tu veuilles faire une fonctionnalité sur ton site mais que tu ne veuilles pas modifier ton code initial, celui qui est en ligne. Il te faudrait une sorte de dimension parallèle… Et bien c’est exactement la définition des branches.
Les branches permettent un historique non linéaire, donc de travailler sur une fonctionnalité particulière sans polluer ton code principal.
Pour cela on fait tout avec la commande :
git branchPour que tout soit clair commençons par
Créer une nouvelle branche
Pour faire ça on utilise :
git branch nom-de-la-nouvelle-brancheOn peut également renommer une branche avec :
git branch -m nouveau-nom-de-branchedans notre projet on va faire :
git branch add-page-storyPour voir toutes nos branches on va venir faire :
git branch
On voit donc que l’on a deux branches, la branche “add-page-story” que l’on vient juste de créer, et une branche “master” (ou “main” selon la version de git) avec un petite * à coté.
La branche “master” (ou “main”) est la branche principale du projet, c’est celle que l’on va mettre en production et qui apparaîtra sur le web.
La petite * signifie que c’est la branche sur laquelle nous sommes.
Ici nous sommes donc sur la branche “master”, branche principale du projet.
Changer de branche
Allons donc sur la branche “add-page-story” avec une commande que nous avons déjà vu :
git checkout add-page-storyJe l’ai dis plus haut, la commande git checkout permet de changer de branche.
Avec un autre :
git branch
On voit que l’on est sur notre nouvelle branche.
Tout ça c’est bien mais… et ?
Et bien maintenant on peut faire nos modifications sans peur d’abimer notre code qui fonctionne et qui tourne sur le web.
Comme le dit le nom de la branche nous allons ajouter un fichier au projet :
touch story.htmlOn le stage et on le commit :
git add --all
git commit -m "add story.htmlMaintenant revenons sur notre branche principale :
git checkout master
Aucune trace de “story.html” !
Il est dans la dimension “add-page-story”.
Faisons une modification sur indexDeux.html : on ajoute un “h3” et on commit :
<h3>bonjour</h3>git add --all
git commit -m "add h3 in index.html"Pour visualiser les branches on peut imaginer un shéma comme cela :

La branche “add-page-story” contient un commit qui n’existe pas sur “master” et “master” a un commit inexistant sur “add-page-story”.
Maintenant que nous avons fait notre nouvelle fonctionnalité (ajouter la page story) et qu’elle fonctionne, il faut les fusionner.
Fusionner les branches
On va appeler ça merger.
Quand on merge une branche, on ramène une branche sur une autre et ainsi on la fusionne.
On utilise :
git merge nom-de-la-branche-à-fusionner-sur-la-branche-couranteOn doit toujours se mettre sur la branche sur laquelle on veut fusionner une autre branche.
Lors d’un merge, la branche source récupère l’historique de la branche.
Donc dans notre cas on va se mettre sur la branche “master” :
git checkout masterPuis merger :
git merge add-page-storyOn vient de rammener “add-page-story” sur “master” :

Et si on regarde nos fichiers on a bien notre fichier story.html qui est là et notre h3 dans indexDeux.html.
Magique non ? 🧙🏼♂️
Maintenant on a plus besoin de notre branche, on va pouvoir la supprimer.
Supprimer une branche
Tout simplement avec :
git branch -d nom-de-la-brancheBien sûr si on supprime une branche sans l’avoir mergé, on perd tout ce qu’il y a dessus ! Donc ❗ Attention ❗
Pour faire cela on doit faire :
git branch -D nom-de-la-brancheEt voilà ! tu es devenu un pro des branches !
Manipuler l’historique
Ce n’est pas vraiment conseillé, mais des fois on peut en avoir besoin pour corriger un commit foireux ou pour préparer une branche avant de la merger.
AMEND
Amend est un argument de git commit, il permet de rajouter des fichier dans la zone de staging et l’inclure dans le commit précédent. Ca permet de corriger un oubli dans le dernier commit et de ne pas faire plusieurs commits pour la même chose.
git commit --amendSi on reprend notre projet, on se souvient que dans notre “indexDeux.html” on avait :
<h1>PAGE ACCUEIL</h1>
<h2>Git workflow</h2>
<h2>Je suis un h2</h2>
<h3>bonjour</h3>Si on vient enlever le <h3> et un <h2> et qu’on les commit :
git commit -a -m "clean indexDeux"il nous reste seulement un <h1> et un <h2>.
Imaginons que nous avons oublié ce dernier <h2> lors de notre commit de “clean”, on va alors le supprimer à son tour et pour réparer cet oubli on va l’inclure dans notre dernier commit :
git add indexDeux.html
git commit --amendOn a donc le même éditeur Vim que lors du revert, que l’on peut alors sauvegarder puis fermer.
On voit donc bien que notre dernier commit est :

Et c’est lui qui contient alors toutes nos dernières modifications, même si on les a fait en deux fois.
❗ Il faut faire attention à ne jamais amend un commit déjà publié ! On l’utilise seulement pour de petits oublis en local ! ❗
REBASE
La commande rebase a le même objectif que merge. La différence est que rebase permet de garder un historique linéaire et garde ainsi tous les commits.
Si, avec un merge, on ramène tout sur la branche “master” (par exemple) sous forme d’un :

Rebase va permettre d’ajouter tous les commits de la branche (“ici add-page-story”) à la suite des commits de la branche “master”.
On va faire un petit exemple pour bien comprendre.
Faisons une nouvelle branche “test-merge” et allons dessus :
git branch test-merge
git checkout test-mergeSupprimons “story.html” puis faisons un commit :
git commit -a -m "del story.html"On revient sur master :
git checkout masterpuis on ajoute un fichier “bonjour.md” :
touch bonjour.mdOn stage notre modification puis on la commit :
git add --all
git commit -m "add bonjour.md"On a donc ça :

Maintenant on va merger “test-merge” sur master :
git merge test-merge
On voit qu’on a une nouvelle entrée dans notre historique de master qui est “Merge branch ‘test-merge’. Ce n’est pas très beau et surtout on perd tout l’historique de la branche “test-merge”.
On va regarder ce que change rebase.
On va commencer par faire une nouvelle branche “test-rebase” :
git branch test-rebase
git checkout test-rebaseSupprimons “contact.html” puis faisons un commit :
git commit -a -m "del contact.html"et ajoutons “navbar.html” puis faisons un commit :
git add --all
git commit -m "add navbar.html"On revient sur master :
git checkout masterpuis on ajoute un fichier “rebase.md” :
touch rebase.mdOn stage notre modification puis on la commit :
git add --all
git commit -m "add rebase.md"On a donc ça :

Maintenant on va rebase “test-rebase” sur master :
On doit se mettre sur la branche que l’on veut rebase !
git checkout test-rebase
git rebase masterLe rebase a bien eu lieu, maintenant on doit ramener master au niveau de “test-rebase” avec un merge classique :
git checkout master
git merge test-rebase
On voit bien que l’on a gardé tout notre historique. On a “add navbar.html”, “del contact.html” et “add rebase.md” au lieu d’un (très moche) Merge branch ‘test-rebase”.
Et on oublie pas de supprimer nos branches 😉 :
git branch -d test-merge
git branch -d test-rebaseREBASE interactif
Un rebase interactif fonctionne exactement comme un rebase classique à ceci près que l’on peut manipuler les commits comme on le veut.
Tout simplement si l’on fait un :
git rebase -i 'nom-de-la-branche'Git va ouvrir un éditeur Vim comme ceci :
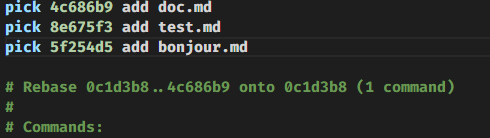
Ou on va pouvoir modifier les commits avec ces commandes :
pick // permet de d'inclure le commit. On peut en profiter pour changer l'ordre des différents commit
reword // permet d'inclure le commit tout en ayant la possibiliter de changer le message
edit // permet d'éditer le commit. En séparant en plusieurs commits par exemple
squash // combine le commit avec le commit du dessus et permet de changer le message du commit
fixup // comme squash mais utilisera le message du commit situé au dessus
exec // permet de lancer des commandes shell sur le commitLe remisage
Le remisage est le fait de mettre de côté temporairement nos modifications sans les commit si l’on veut par exemple changer de branche pour intervenir sur autre chose.
STASH
Elle va être utilisée pour mettre de côté toutes les modifications qui ont été apportées au projet depuis le dernier commit.
git stashSi on fait un coup de git status on verra qu’il n’y a plus rien dans les fichiers modifiés.
STASH APPLY
Pour réappliquer nos modifications stashées on utilise :
git stash applySTASH LIST
On peut voir tous les stash sauvegardés avec :
git stash listSTASH DROP
Même lorsqu’il est ”apply”, le stash ne disparaîtra pas de la liste, pour supprimer le dernier stash on utilise :
git stash dropSTASH POP
Cela permet de faire les commandes git stash apply et git stash drop en une seule ligne :
git stash popSTASH multiple
Si l’on a plusieurs stash en mémoire on va pouvoir les appeler par stash@{id}, par exemple :
git stash apply stash@{1}On peut également avoir plus d’informations sur un stash avec :
git stash show stash@{1} -pet les nommer avec :
git stash save "fix bug form"Mais tu n’avais pas parler de travailler à plusieurs ?
…parce que pour l’instant on ne travaille qu’en local… 🤔
Et bien si !
Et c’est ce qu’on va voir maintenant.
On va introduire des nouvelles notions, la première c’est le notion de dépot.
Depuis le début on travaille dans un dossier (“premier-projet-git”), c’est notre dépot local.
Pour pouvoir travailler à distance et collaborer on va utiliser un dépot distant.
Pour faire un dépot distant on peut utiliser un dossier spécifique, un chemin ssh:// ou un service comme Github, Gitlab ou Bitbucket.
Dépot distant
Pour prendre tes marques je te propose de commencer sur un dossier sur ta machine qui nous servira de dépot distant.
Pour cela, lorsque on initialise Git dans un dossier, on peut rajouter un argument --bare :
git init --bareDonc crééons ce dossier (en dehors de notre dossier “premier-projet-git”) :
mkdir remote
cd ./remote/Puis on l’initialise :
git init --bareC’est un dossier Git qui n’aura pas de dossier de travail, il servira seulement de dépot distant.
Pour ajouter une connexion de notre projet (dépot local) à notre dépot distant on dit qu’on fait une ”remote“.
REMOTE
Pour en ajouter une on fait (sur le terminal de notre dépot local) :
git remote add origin "dépot-distant"Ici :
git remote add origin "C:\Users\coren\Desktop\remote"”origin” est le nom que l’on donne à notre dépot, par convention on le nomme “origin” pour dépot originel.
Pour voir les connexions on fait :
git remote -vOn peut le renommer avec :
git remote rename "nouveau-nom"Et le supprimer avec :
git remote remove "nom-du-dépot"Pour voir les branches distantes on fait :
git branch -r(ici on aura rien puisque on encore rien envoyé sur notre dépot distant)
PUSH
Pour envoyer sur notre dépot distant on fait :
git push "nom-du-dépot-distant" "nom-de-la-branche"
// ou
git push --all // pour pousser toutes les branchesIci :
git push origin masterAvec :
git branch -rOn a bien notre branche master sur origin :

On peut réessayer avec une nouvelle branche :
git branch test // on créé une nouvelle branche
git push origin test // on l'envoie sur origin
git branch -r // on a notre nouvelle branchePour la supprimer on la supprime d’abord en local :
git branch -d testPuis pour le dépot distant :
git push origin --delete testpush permet donc d’envoyer les modifications.
PULL
Pour récupérer les nouvelles informations qui ont eu lieu sur le dossier distant (par exemple parce que Michel à fait une nouvelle modif.) on utilise :
git pull "nom-du-dépot-distant" "nom-de-la-branche"Ici :
git pull origin masterpull permet de récupérer les modifications.
(Option) Pour obliger Git à faire des rebase plutôt que des merge lors des pull, on peut modifier la configuration en faisant :
git config --global branch.autosetuprebase alwaysCLONE
Pour créer un nouveau projet à partir d’un dépot distant il faudra utiliser :
git clone "lien-dépot-distant"On peut donner une profondeur à un clone pour ne pas récupérer tout un énorme historique avec la commande :
git clone "lien-dépot-distant" --depth "nombre-de-commit-précédent-à-récupérer"Services d’hébergement, Github & cie
Github, Gitlab, Bitbucket, …
Tous ces services sont des services d’hébergement.
Ils donnent accès à des dépots distants.
C’est grâce à eux que tu pourras bosser avec Michel, Raph, Cédric ou sur le projet open-source.
Ici on va parler plus particulièrement de Github.
Rapidement, Github est développé par Chris Wanstrath, PJ Hyett et Tom Preston-Werner en 2008, c’est toujours le service d’hébergement de ce type préféré de beaucoup de développeurs.
Je te propose de te créer un compte sur le site de Github : www.github.com.
Si tu ne comprends pas tout c’est normal, ce qui va nous intéresser ici (tu pourras découvrir le reste tout seul), c’est les ”repositories”, c’est tout bonnement l’équivalent de notre dossier “remote” de tout à l’heure, ça va être tes dépots distants.
Clé SSH
Avant de commencer à l’utiliser on va tout d’abord générer une clé ssh (c’est la clé que l’on va donner à Github.) :
ssh-keygen -t rsa -C "ton-email" // entre ""Il va te demander le chemin sur lequel tu veux le mettre, je te conseil : ”C:\Users/nom-d'utilisateur“.
Si tu vas dans ton explorateur de fichiers et dans ”C:\Users/nom-d'utilisateur/.ssh” id devrait y avoir deux fichiers : ”id_rsa” et ”id_rsa.pub“.
La clé ”id_rsa” est secrète et il ne faut la donner à personne !
La clé ”id_rsa.pub” est la clé publique, c’est elle que l’on va utiliser.
Si on l’ouvre avec un éditeur de texte on a une longue clé cryptée.
Et bien on va la copier puis la coller dans l’onglet “Settings”/“SSH and GPG keys”/“New SSH key” de Github et l’ajouter.
Nouveau repository
On va commencer par créer un nouveau dépot local pour repartir de zéro :
mkdir projet-git-github
cd projet-git-githubOn va initialiser Git, créer un nouveau fichier readme.md, le remplir et on va le commit :
git init
touch readme.md
// on met le nom du projet dedans "# projet-git-github"
git add --all
git commit -m "initial commit"Sur Github on va commencer par créer un nouveau dépot, un nouveau ”repository“.
Ca se passe en haut à droite, lorsque tu cliques sur l’icone utilisateur, tu peux choisir l’onglet “Your repositories”. Et à droite tu as New.
Tu peux donner le nom que tu veux à ton repo (nom abrégé chez les devs 😉) mais ici on va mettre ”projet-git-github”, on va le mettre en privé et le créer.
Bravo ! Tu as créé ton premier repo !
Sur la page de ton repo tu vas avoir le choix entre plusieurs choses. Nous on va utiliser la méthode HTTPS et donc copier le lien HTTPS.
C’est ici que l’on va ajouter une “remote”, avec ce lien là :
git remote add origin https://github.com/Corentin7301/projet-git-github.gitEt pousser notre commit sur notre dépot distant :
git push origin main // ma branche s'appelle "main"Maintenant si tu retourne sur Github et que tu rafraichis la page, tu peux voir ton magnifique readme qui apparaît !
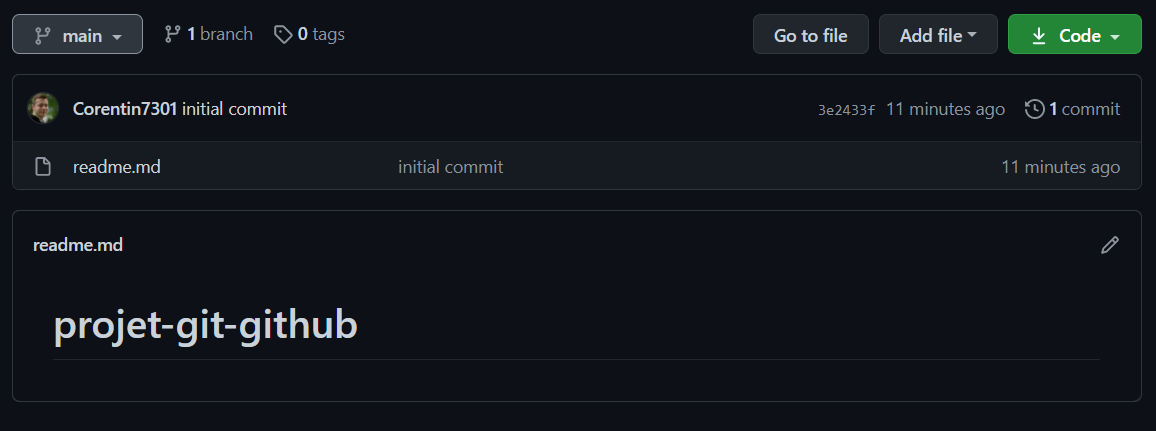
Presque magique non ? 🧙🏼♂️😉
A partir d’ici tout le monde pourra mettre une star (aimer), devenir watcher (s’abonner) ou forker (on le verra juste après).
(Enfin, pas sur notre projet puisqu’il est en privé)
On peut également voir le code, les commits et les branches directement en ligne.
Sur Github on a également un système d’issues, en gros, ça sert à signaler un bug sur l’application.
C’est grâce à cela que le(s) développeur(s) pourront résoudre les problèmes.
FORK
Imaginons que tu veuilles mettre ton projet en ligne sur Github et que tu le mets en public. C’est bien joli mais tu te doute bien que si ton projet grossi et s’il a des bugs, des gens voudront t’aider à les réparer (c’est le but de l’open source).
Ca voudrait dire qu’ils feraient comme on vient de faire, on clone le repository sur notre machine et on bosse dessus, quand on a fini on fait un petit coup de push et ça retourne sur Github.
Oui mais… EH ! Paul ! Tu viens de péter ma production en commitant sur master là ! Il est pas bon ton commit en plus !
Eh oui… on est d’accord, tout le monde ne peut pas faire ce qu’il veut sur ton projet.
Alors pour régler ça, Paul ne va plus cloner ton repo, mais le forker.
Si tu regardes ce repository par exemple : github o79-community.
Si tu regardes en haut à droite, tu verras un bouton ”fork”. Et bien c’est ça !
Forker c’est créer un nouveau repository similaire mais qui va appartenir à la personne qui fork.
Si tu appuies sur le bouton (vas y je te laisse faire 😉) tu vas créer une copie du repo de Xlanex6 sur ton espace de repositories.
Et cette fois, celui-ci, tu vas pouvoir le cloner.
Si on fait un git log --oneline dans ce dossier, on peut voir que l’on récupère également tout l’historique :
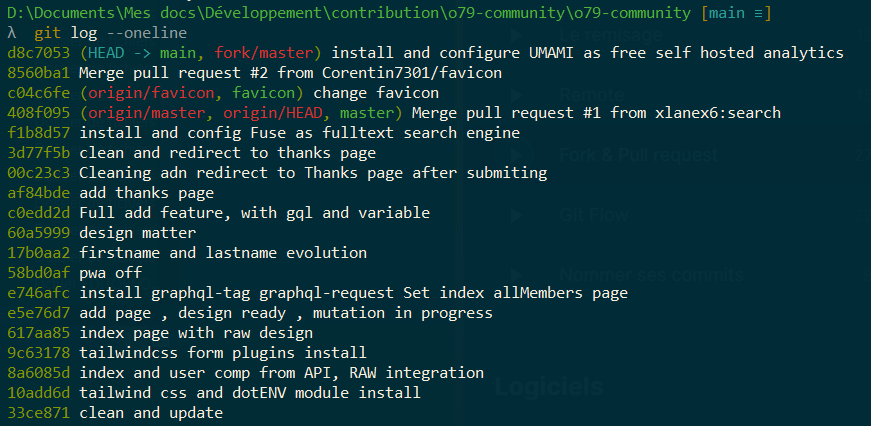
On peut aussi essayer de lister toutes les branches :
git branch -a
Lorsqu’on commence à travailler sur un fork il faut tout de suite créer une nouvelle branche !!
Et ne jamais travailler sur master (ou main)
PULL REQUEST
On va maintenant laisser tranquille le repo de Xlanex6.
Je t’invite à forker ce repo : https://github.com/Corentin7301/tuto-projet-git-github
(Oui c’est le mien, alors si tu veux laisser une petite star ⭐ ou me Follow n’hésites pas 😉)
Donc si on réutilise ce qu’on a fait avant, on appuie sur le bouton ”fork” puis on le clone sur notre machine.
Une fois que c’est fait on va faire une nouvelle branche :
git branch readme
git checkout readmeEt on va ajouter “Bonjour à tous sur mon projet” dans le readme.
On va pouvoir faire un commit :
git add --all
git commit -m "add hello in readme"Maintenant on va push notre branche sur Github, et par conséquent la soumettre à l’auteur.
git push origin readmeSi on retourne sur Github on va voir un nouveau bouton vert avec écrit ”Compare & pull request“.
C’est ici que l’auteur va pouvoir voir tes modifications, les accepter ou non, te dire pourquoi, échanger avec toi dessus.
Et toi, à chaque nouvelle modification, il te suffis de commit puis de push pour que la pull request se mette à jour.
Remettre à jour le dépot forké
Maintenant imaginons que tu délaisses le projet pendant un moment, le monde ne s’arrête pas de tourner (non non 😉), le projet avance. Mais toi tu n’est plus à jour !
Alors pour le remettre à jour on ne va pas supprimer notre dépot, le re-forker puis le re-cloner (t’imagines ?!). Non, on va faire une nouvelle remote avec cette fois l’url du dépot original (pas le tiens, celui que tu as fork) :
git remote add upstream https://github.com/Corentin7301/projet-git-github.gitupstream est le nom donné par convention pour cette remote.
Si on fait :
git remote -vIl doit y avoir les deux remotes.
Si on fait :
git branch -aIl n’y a pas accès aux branches de “upstream”.
Pour cela on va récupérer la branche master qui se trouve sur “upstream” :
git fetch upstreamSi on refait :
git branch -aOn a maintenant les branches de upstream.
Maintenant on peut se mettre sur notre branche master et merger la branche upstream/master :
git merge upstream/masterEt c’est tout bon, maintenant, à chaque fois qu’il faudra remettre à jour, il suffira de merger.
Je conseille, à chaque fork, de faire cette manipulation pour ne plus avoir à y penser ensuite.
IMPORTANT
Je conseille de ne JAMAIS faire de commit sur master | main et de la garder pour les synchronisations. On utilise plutôt d’autres branches pour travailler.
Logiciels
Pour terminer je vais parler de quelques logiciels qui facilitent l’utilisation de git lorsque l’on est pas très à l’aise avec le terminal (même si après cet article ça m’étonnerais 🤔).
Octotree
Cette extension est une aide précieuse dans Github, elle permet de naviguer entre tous les dossiers d’un projet rapidement et efficacement.
Sur la capture d’écran, c’est l’onglet qui est ouvert à gauche de l’écran.

Github Desktop
Tout d’abord, Github Desktop est un client Github qui va permettre de ne presque plus passer par les lignes de commandes.
L’interface est très simple et en quelques minutes tu vas en comprendre le fonctionnement.
GitKraken
Dans la même lignée on retrouve GitKraken. C’est avec cet outil que j’ai pu faire les demonstrations de merge et de fork.

Il est également très simple et joli. Mais ce qui fait sa grande force c’est son système de visualisation de l’historique qui rend la compréhension des branches bien plus simple.
Source Tree
Il existe aussi Source Tree que j’ai utilisé pendant un moment mais que j’ai laissé tomber à cause de sa lenteur de son habitude de crasher.

L’interface est un peu plus brute que sur les deux autres mais il reste efficace. Le système de branches est sympa même si celui de GitKraken est plus élaboré.
VS Code
Dans l’éditeur de code VS Code, on retrouve tout un panneau concernant Git (à droite sur la capture d’écran).

Le gros avantage est que son utilisation s’intègre dans le workflow de l’utilisateur puisqu’il reste sur le même logiciel.
La gestion de Git via ce panneau est simple et surtout efficace. Le désavantage est qu’il n’y a aucune interface graphique ni représentation de l’historique sous la forme de branches.
Mon avis
Personnellement j’utilise aujourd’hui la solution de VS Code, qui me permet de ne pas avoir à changer de logiciel et s’inclut dans mon workflow, mais je conseille l’utilisation de GitKraken qui est assez complet et qui facilite la gestion des branches.
Git Cheat Sheet | Aide-mémoire Git
git --version // connaitre sa version de Git
git help // permet d'ouvrir la doc
// BASH COMMAND
cd ton/chemin // aller à ce chemin
mkdir nom-du-nouveau-dossier // créer un nouveau dossier
touch nom-du-nouveau-fichier // créer un nouveau fichier
// GIT COMMAND
// GIT CONFIG
git config --global user.name "Nom Prénom" // configurer son username
git config --global user.email "nom@exemple.com" // configurer son email
git config --global branch.autosetuprebase always // Obliger Git à faire de rebase plutôt que des merges lors des pull
// GIT INIT
git init // initialiser un projet Git
git init --bare // initialiser un projet distant
// GIT STATUS
git status // regarder l'état de notre projet
// GIT ADD
git add fichier.extension // ajouter un fichier à la zone de staging
git add --all // ajouter tous les fichiers à la zone de staging
// GIT COMMIT
git commit -m "nom-du-commit" // ajouter un commit
git commit -a -m "nom-du-commit" // ajouter un commit en ajoutant tous les fichiers dans la zone de staging
git commit --amend // Permet de rajouter des fichier dans la zone de staging et l'inclure dans le commit précédent.
// GIT LOG
git log // permet de voir les commits
git log --oneline // permet de voir les commits sur une ligne
git log --oneline -p nom-du-fichier // permet de voir les modifications depuis le dernier commit sur un fichier
// GIT DIFF
git diff // permet de voir la différence avec le dernier commit
// GIT CHECKOUT
git checkout id-commit | id-branch // changer de branche | revenir sur un commit | revenir sur un fichier par rapport à un commit
// GIT REVERT
git revert f385eae // permet de défaire un commit
// GIT RESET
git reset id-commit // Supprime un fichier de la zone de staging mais pas les modifications qui sont faites.
git reset // Supprime tous les fichiers de la zone de staging mais pas les modifications qui sont faites.
git reset --hard // ❗ Renvoit le dossier de travail au niveau du dernier commit. Toutes les modifications non commit seront perdues.
git reset id-commit // Permet de revenir en arrière jusqu'au commit en question, réinitialise la zone de staging tout en laissant votre dossier de travail en l'état.
git reset id-commit --hard // ❗ Permet de revenir au commit en question et réinitialise la zone de staging et le dossier de travail pour correspondre.
// GIT BRANCH
git branch nom-de-la-nouvelle-branche // Permet de créer une nouvelle branche
git branch // Permet de voir toutes les branches
git branch -d nom-de-la-branche // Supprime la branche (sauf si elle n'a pas été mergée)
git branch -D nom-de-la-branche // ❗ Supprime la beanche en force
git branch -r // Permet de voir les branches distantes
git branch -a // Permet de lister toutes les branches
// GIT MERGE
git merge nom-de-la-branche-à-fusionner-sur-la-branche-courante // Permet de fusionner les branches
// GIT REBASE
git rebase master // Permet de fusionner la branche en gardant un historique linéaire et en récupérant tous les commits de cette branche
git rebase -i 'nom-de-la-branche' // Permet de faire un rebase interactif
// GIT STASH
git stash // Permet de remiser les modifications
git stash apply // Permet de réappliquer les modifications
git stash list // Permet de lister les stash
git stash drop // Permet de supprimer un stash
git stash pop // Permet de faire un apply puis un drop
git stash ----- stash@{1} // Permet d'utiliser un seul stash
git stash show stash@{1} -p // Permet d'avoir des informations sur un stash
git stash save "fix bug form" // permet de nommer un stash
// GIT REMOTE
git remote add origin "dépot-distant" // Ajouter une remote/connexion
git remote -v // Voir les remotes/connexions
git remote rename "nouveau-nom" // Renommer une remote/connexion
git remote remove "nom-du-dépot" // Supprimer une remote/connexion
// GIT PUSH
git push "nom-du-dépot-distant" "nom-de-la-branche" // Envoyer une branche sur le dépot distant
git push --all //Permet d'envoyer toutes les branches
git push origin --delete nom-de-la-branche // Supprimer une branche distante
// GIT PULL
git pull "nom-du-dépot-distant" "nom-de-la-branche" // Récupérer les informations depuis le dépot distant
// GIT CLONE
git clone "lien-dépot-distant" // Permet de récupérer un dépot distant sur une machine
git clone "lien-dépot-distant" --depth "nombre-de-commit-précédent-à-récupérer" // Permet de récupérer seulement que quelques commit et non tou l'historique
// GIT FETCH
git fetch nom-du-depot // Permet de récupérer des branches depuis un autre dépot
// CLE SSH
ssh-keygen -t rsa -C "ton-email" // Permet de générer une clé SSH